

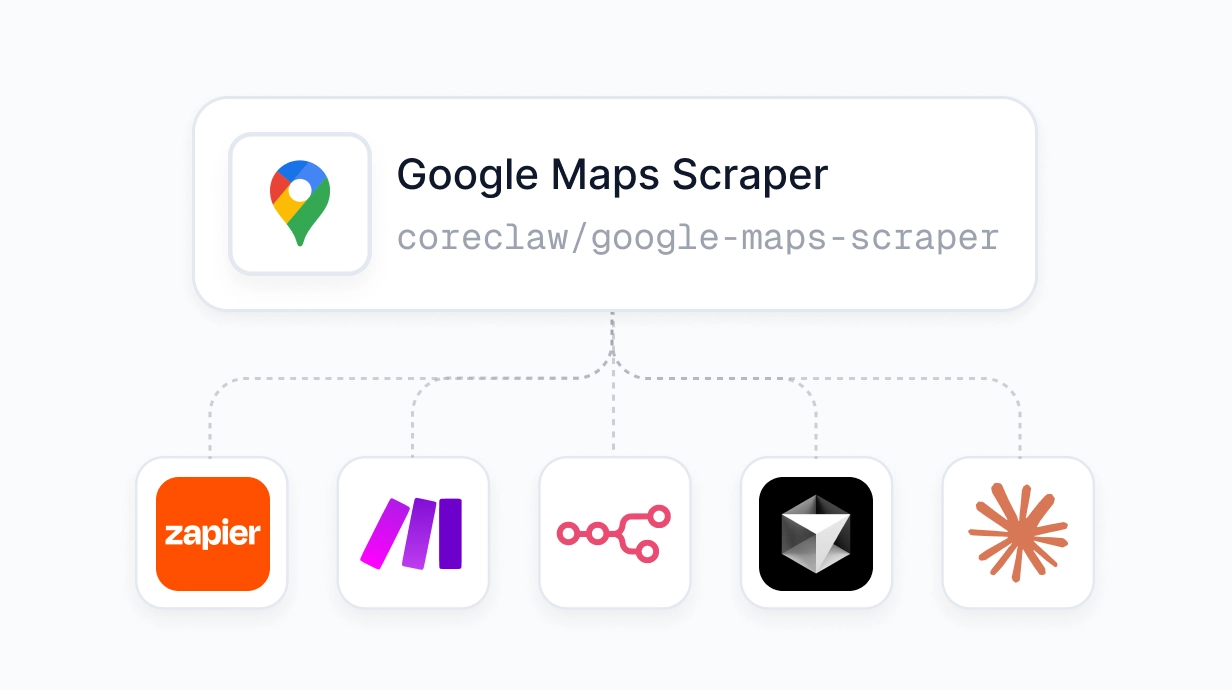
系统集成
抓取数据后,可同步或异步推送至 Zapier、Make、n8n 等自动化平台进行后续处理;也可通过 MCP 协议接入 Claude、Cursor、VS Code 等 AI 工具,供直接调用。
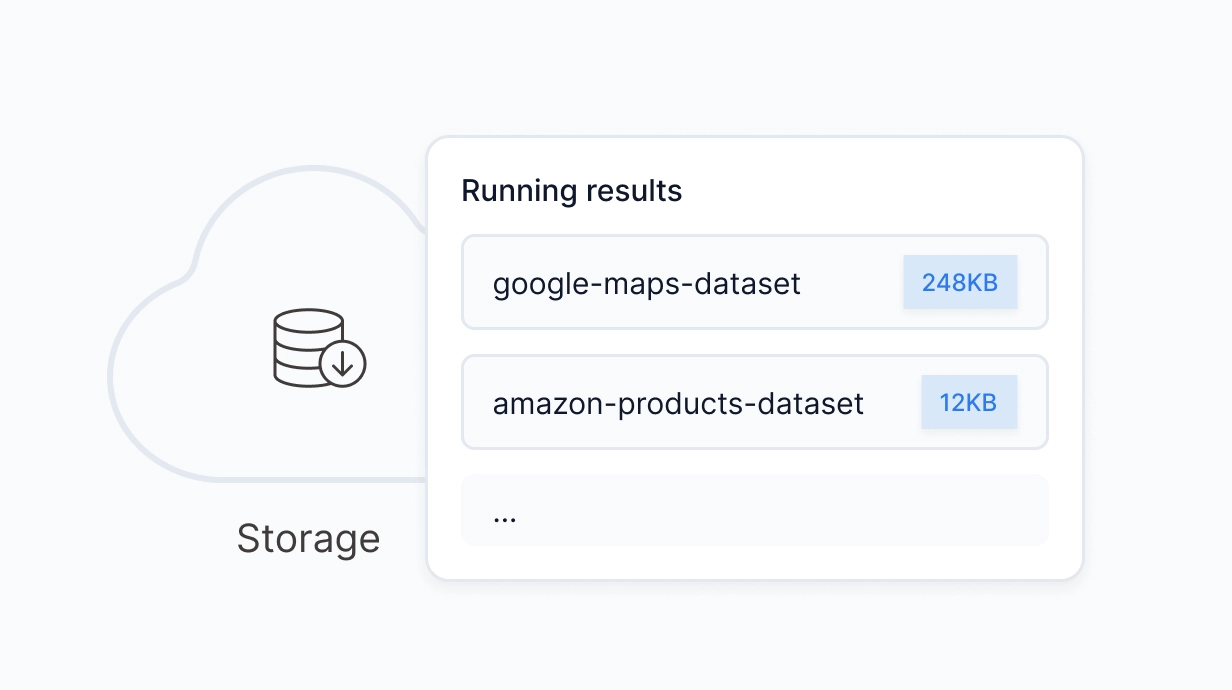
Workers 是开发者用来抓取网页数据的自动化工具。支持云端或本地运行,自动完成数据采集与提取,可通过 API 按需触发或获取结果——无需操心任何基础设施。
Workers 可处理耗时较长的任务,不受单次请求超时限制。自动化流程稳定高效运行——你无需投入任何精力管理基础设施。
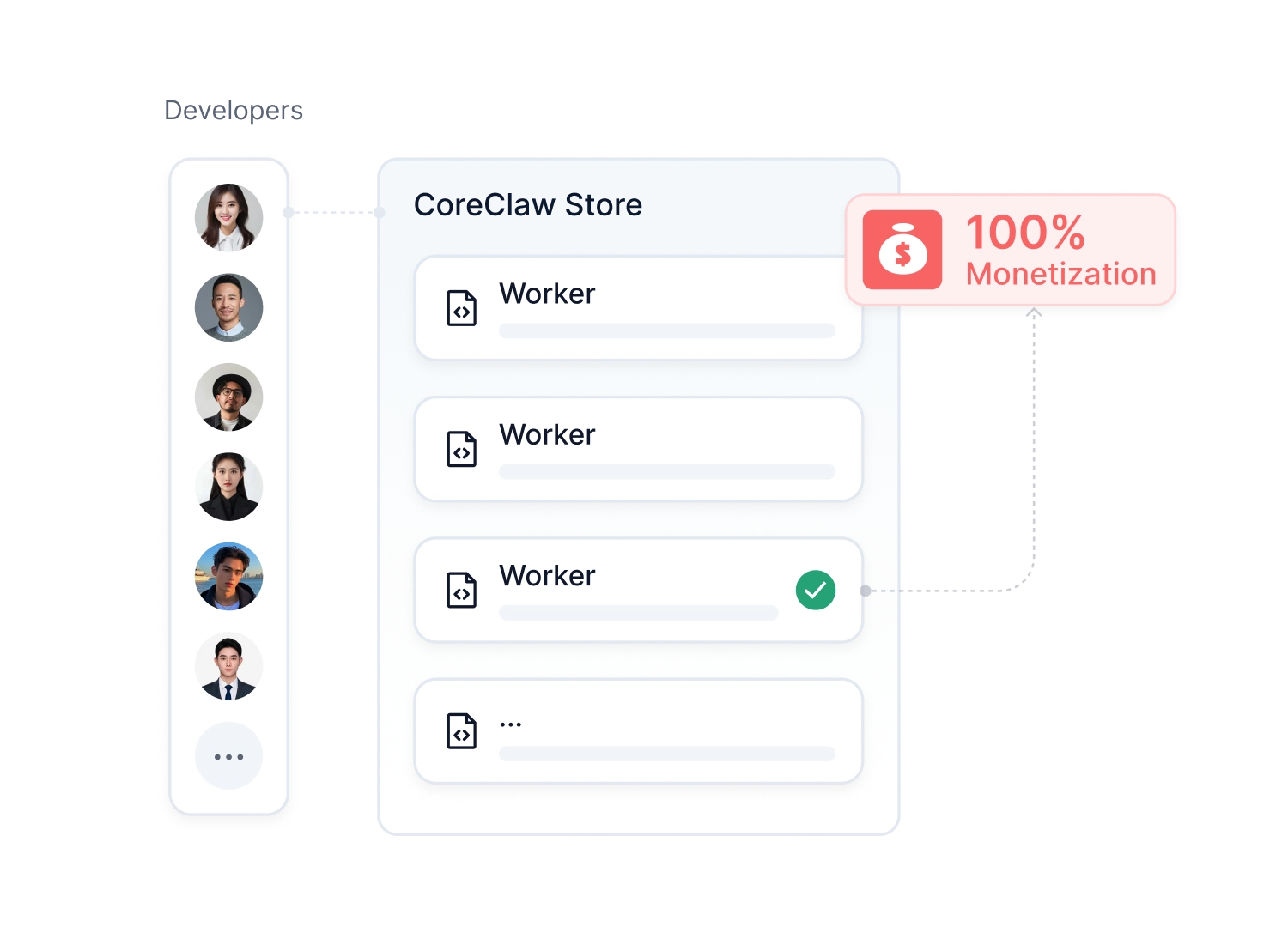
将 Workers 发布到 CoreClaw Store,获得持续的收入来源。
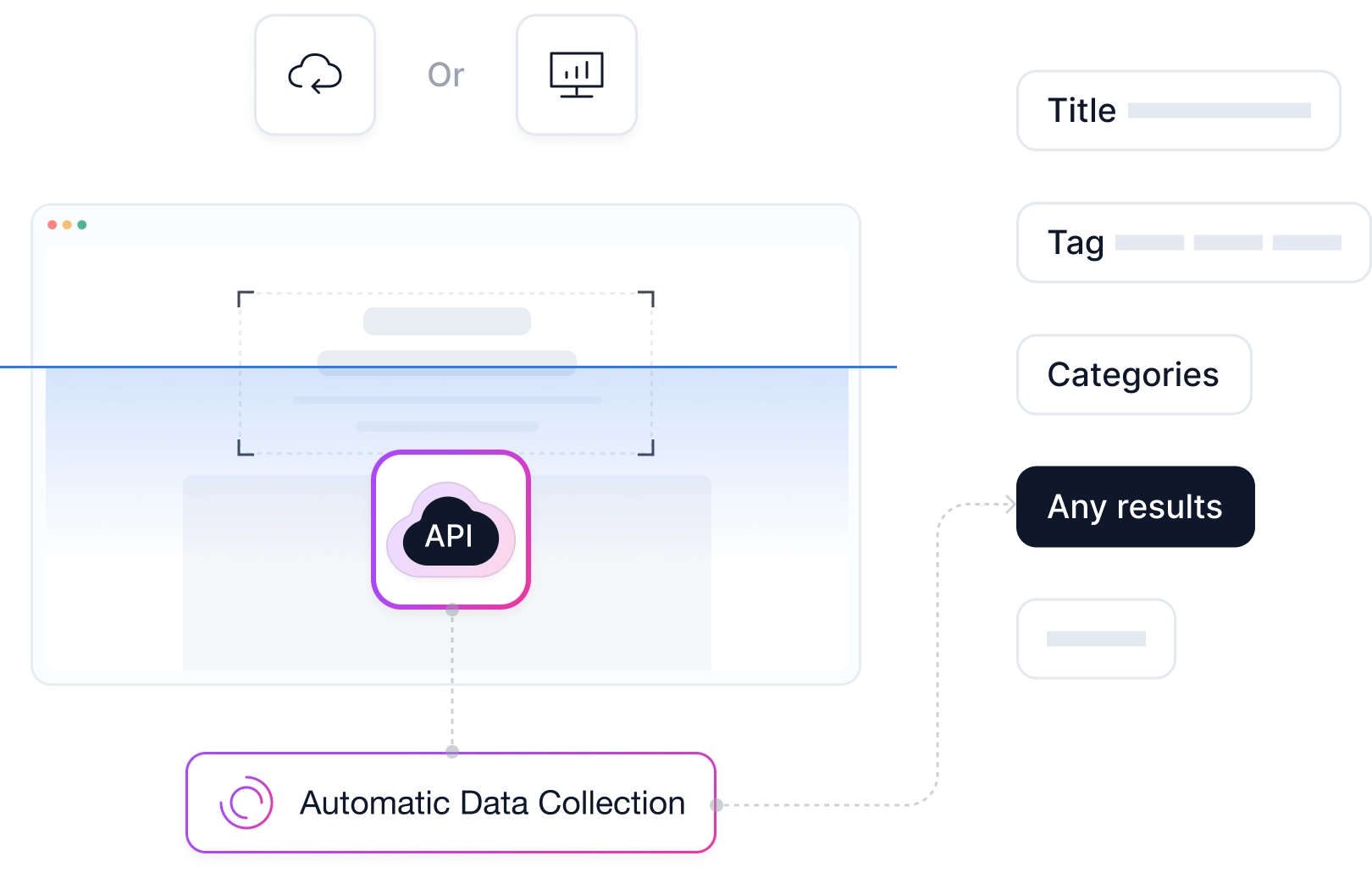
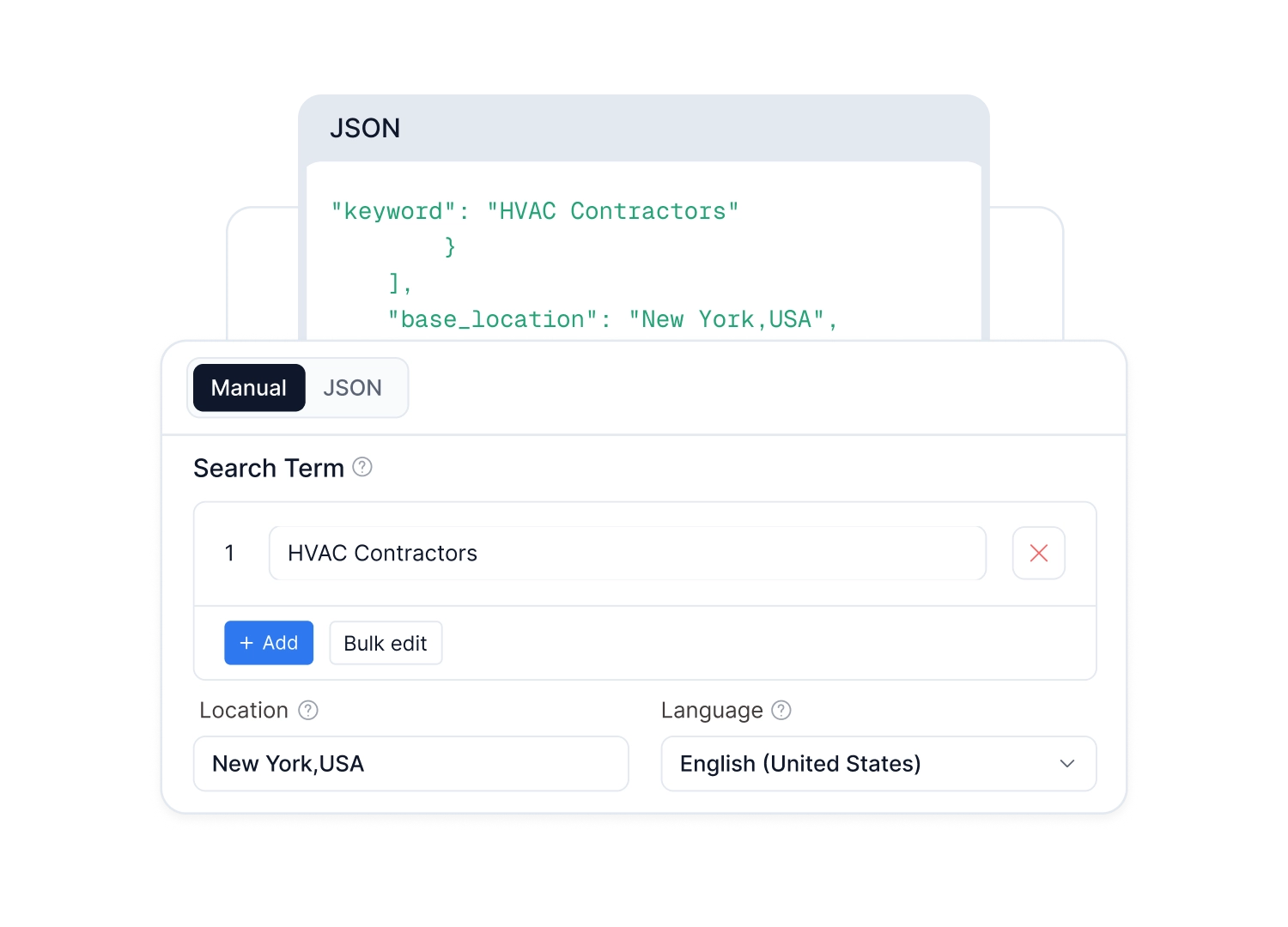
只需完成简单的参数配置,CoreClaw 便会自动生成完整的执行界面——团队中任何人都能直接上手操作、启动任务。同时也支持 Api 调用,灵活接入任意系统。
Workers 可作为实时 API 持续运行——在后台随时待命,像 Web 服务器一样响应任意 HTTP 请求。
在平台上直接编辑、从 Git 仓库拉取,或上传 ZIP 文件——多种方式灵活选择。
Workers 运行于 Docker 容器中,支持自定义 Dockerfile。
按需自动配置计算资源,无需手动管理基础设施。
为每个 Worker 分配所需内存(RAM),CPU 按比例自动分配。
设置运行计划,让 Workers 在指定时间自动触发,无需人工干预。
支持查看和下载日志,可在生产环境中调试代码、追踪运行详情。
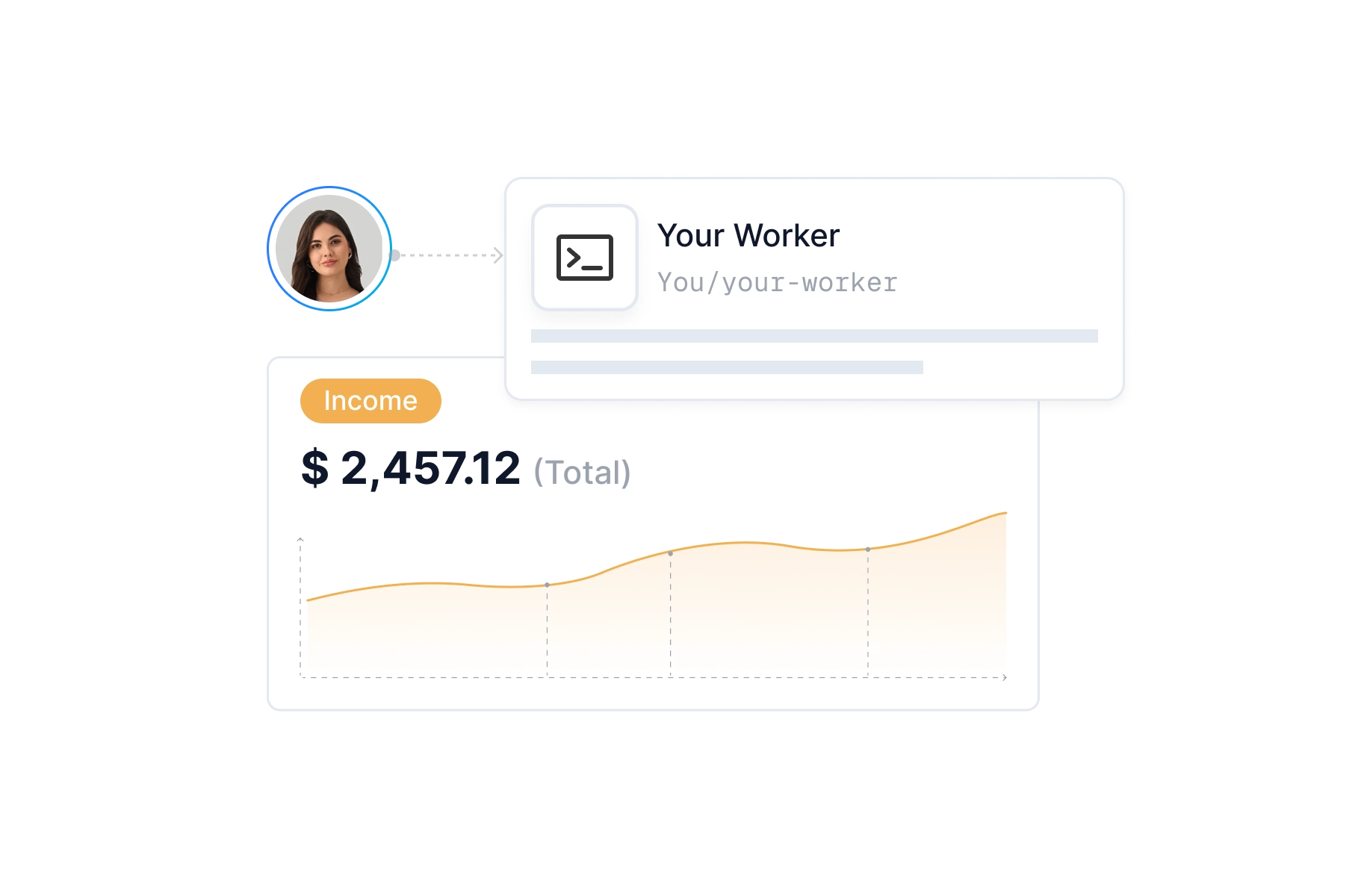
分享你的智慧,获得丰厚回报。将开源 Worker 上架 CoreClaw Store,即可加入激励计划,按使用量持续获取收益。
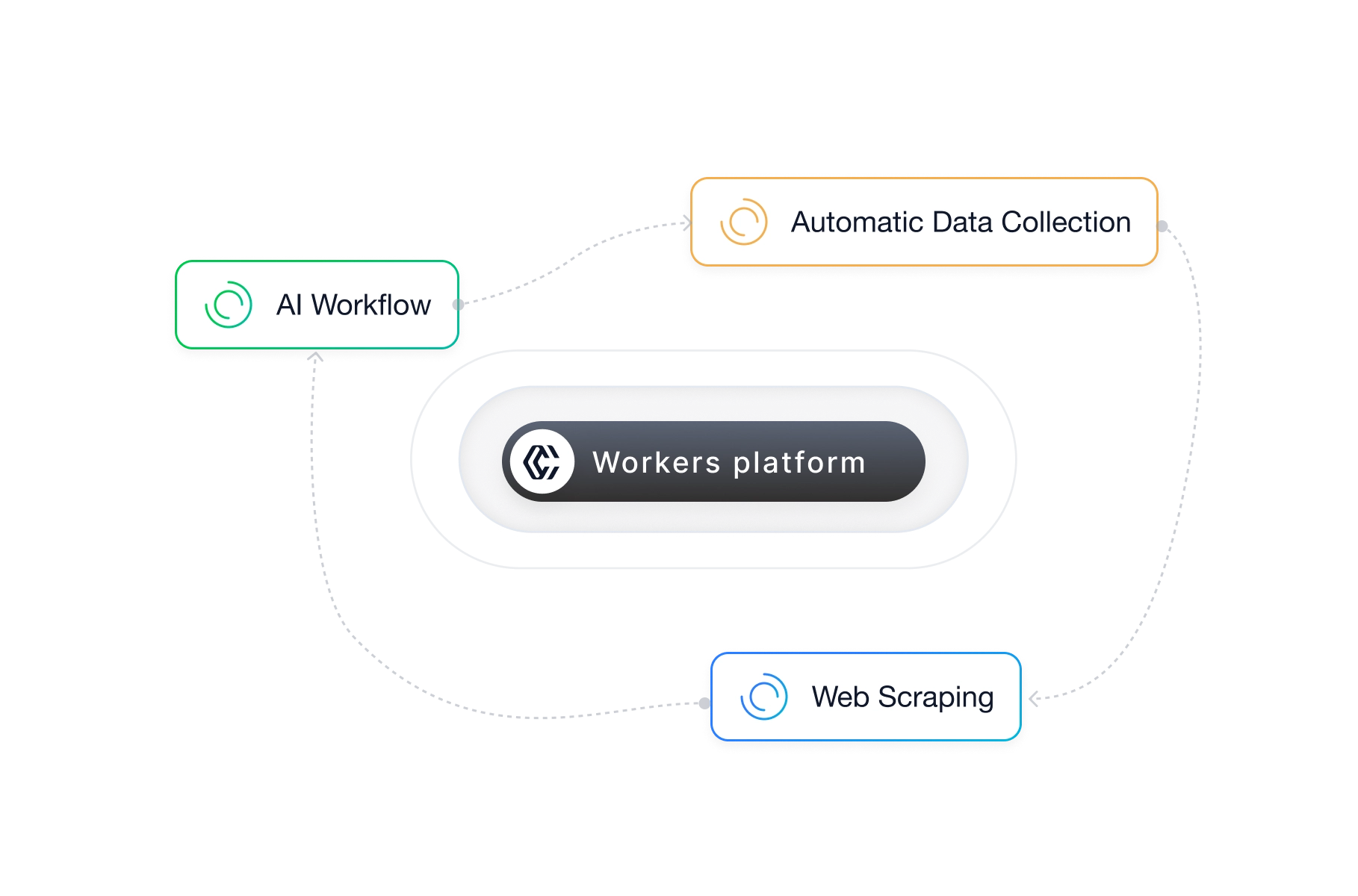
CoreClaw Workers 是轻量级的容器化程序——接收 JSON 输入、执行任务、返回结构化输出。为自动化、网页采集和 AI 工作流提供简单、可组合的云端执行方式。